SereneDB Team
Let compiler cook!
Optimizing ANN search: How fast-math boosted our vector distances
Introduction
Sometimes, when we are thinking of writing an efficient implementation of some basic algorithm, we might go with hand-writing (or maybe claude-writing) SIMD intrinsics. Unfortunately, in some cases it isn't the best approach, and today we are going to have a brief talk about one such case.
Why vector distances matter
Approximate Nearest Neighbor (ANN) search — given a query vector, find the k most similar ones in a large dataset. No matter how smart the search algorithm is, it still boils down to computing a huge number of distances between vectors. That makes the distance function a hot spot: it is called so frequently that even a small speedup there translates directly into faster queries end-to-end.
SereneDB already has a fast full-text search engine[5], and vector search is the next piece needed to enable hybrid search — combining keyword and semantic similarity in a single query.
Vector distances Benchmarks
There are four typical vector distance functions:
- L2 squared distance:
- L1 distance:
- Dot (Inner) product:
- Cosine similarity:
We've added a benchmark to compare our implementations [1] with faiss. All benchmarks run on an AMD Ryzen 9 9950X (Zen 5, 16 cores, 48 KiB L1d per core, 1 MiB L2, 32 MiB L3):
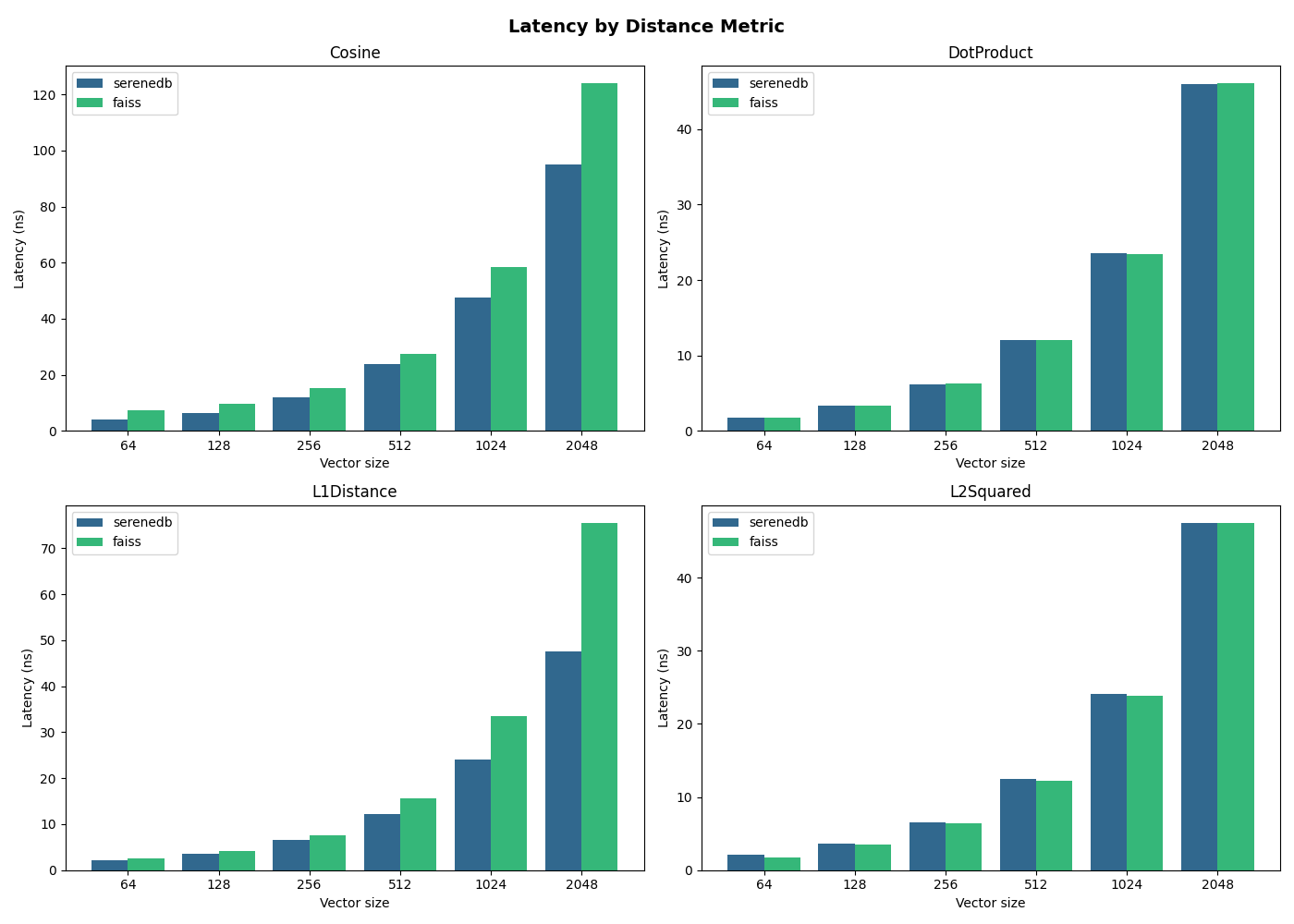
As you can see, dot product and L2 distance take the same time; however, cosine similarity and L1 distance are significantly slower in faiss. Even more, take a look at the SereneDB implementation of L1 distance and the implementation in faiss:
serenedb:
template<typename In, typename Abs, typename Out>
struct L1Space {
static_assert(std::is_signed_v<Abs>);
static Out Dist(const byte_type* l, const byte_type* r, uint16_t d) {
Out s{};
for (uint16_t i = 0; i != d; ++i) {
auto li = static_cast<Abs>(reinterpret_cast<const In*>(l)[i]);
auto ri = static_cast<Abs>(reinterpret_cast<const In*>(r)[i]);
auto lri = li - ri;
s += static_cast<Out>(std::abs(lri));
}
return s;
}
};
faiss:
// #ifdef USE_AVX
float fvec_L1(const float* x, const float* y, size_t d) {
__m256 msum1 = _mm256_setzero_ps();
// signmask used for absolute value
__m256 signmask = _mm256_castsi256_ps(_mm256_set1_epi32(0x7fffffffUL));
while (d >= 8) {
__m256 mx = _mm256_loadu_ps(x);
x += 8;
__m256 my = _mm256_loadu_ps(y);
y += 8;
// subtract
const __m256 a_m_b = _mm256_sub_ps(mx, my);
// find sum of absolute value of distances (manhattan distance)
msum1 = _mm256_add_ps(msum1, _mm256_and_ps(signmask, a_m_b));
d -= 8;
}
__m128 msum2 = _mm256_extractf128_ps(msum1, 1);
msum2 = _mm_add_ps(msum2, _mm256_extractf128_ps(msum1, 0));
__m128 signmask2 = _mm_castsi128_ps(_mm_set1_epi32(0x7fffffffUL));
if (d >= 4) {
__m128 mx = _mm_loadu_ps(x);
x += 4;
__m128 my = _mm_loadu_ps(y);
y += 4;
const __m128 a_m_b = _mm_sub_ps(mx, my);
msum2 = _mm_add_ps(msum2, _mm_and_ps(signmask2, a_m_b));
d -= 4;
}
if (d > 0) {
__m128 mx = masked_read(d, x);
__m128 my = masked_read(d, y);
__m128 a_m_b = _mm_sub_ps(mx, my);
msum2 = _mm_add_ps(msum2, _mm_and_ps(signmask2, a_m_b));
}
msum2 = _mm_hadd_ps(msum2, msum2);
msum2 = _mm_hadd_ps(msum2, msum2);
return _mm_cvtss_f32(msum2);
}
The implementation in SereneDB is much simpler and more convenient, while in faiss there are multiple SIMD intrinsics, so it takes a while to analyze what is actually going on. And yet faiss is still slower than SereneDB — why?
L1 distance SIMD Algorithm
Let's discuss the implementation in faiss (don't worry, it is not that hard).
In the first while-loop, 8 floats are loaded from x into mx and from y into my:
__m256 mx = _mm256_loadu_ps(x);
x += 8;
__m256 my = _mm256_loadu_ps(y);
y += 8;
Then they are subtracted and the most significant bit is set to zero (using signmask) in order to find the absolute value. Afterwards, the value is added to the accumulator msum1:
__m256 signmask = _mm256_castsi256_ps(_mm256_set1_epi32(0x7fffffffUL));
// ...
const __m256 a_m_b = _mm256_sub_ps(mx, my); // subtraction
msum1 = _mm256_add_ps(msum1, /*abs*/ _mm256_and_ps(signmask, a_m_b));
d -= 8;
After the loop, if there are at least 4 floats remaining, the algorithm performs the same procedure as above but with just 4 floats. Finally, it processes the remaining floats.
This approach is faster than a basic implementation without SIMD instructions, because the algorithm processes 8 floats at a time. However, it could be faster.
Fast Math
Now it is time to reveal the root cause of the efficiency of the SereneDB algorithm: fastmath. Here are the extra flags that are set while compiling the SereneDB implementation: -fassociative-math and -fno-signed-zeros
What do the flags mean?
These flags collectively relax the strict rules of the IEEE 754 floating-point standard, giving the compiler more freedom to reorganize and optimize arithmetic. Here is what each one does:
-fassociative-mathallows the compiler to reorder floating-point operations (e.g.(a + b) + cintoa + (b + c)). In reality, floating-point addition is not associative due to rounding, so this can slightly change results, although it enables the compiler to use multiple accumulators in parallel, which is exactly what we will see in the assembly below. This flag is crucial in our case, because it enables vectorization by creating additional accumulators and gaining more parallelization.-fno-signed-zerostells the compiler it may treat -0.0 and +0.0 as identical. This option is actually required to enable-fassociative-math, because addition is not associative with signed zero[3]:
L1 distance with Fast Math
After compiling with those flags, look at the SereneDB algorithm's assembly code: [2]. As you can see, the algorithm is basically the same, nevertheless, it uses 4 256-bit ymm registers to process floats, so due to ILP and operation independence, the load/subtract operations can be processed in parallel. That way we are able to process 16 floats at a time (4 times more than in faiss).
Although, the compiler did not find an optimal way of accumulating the result:
; There are 4 accumulators: ymm0, ymm2, ymm3, ymm4
vaddps ymm0, ymm5, ymm0
vandps ymm5, ymm6, ymm1
vaddps ymm2, ymm5, ymm2
vandps ymm5, ymm7, ymm1
vaddps ymm3, ymm5, ymm3
vandps ymm5, ymm8, ymm1
vaddps ymm4, ymm5, ymm4
It may be faster (and more parallel) to rewrite it as something like:
vaddps ymm0, ymm5, ymm0
vandps ymm6, ymm6, ymm1 ; vandps ymm5, ymm6, ymm1
vaddps ymm2, ymm6, ymm2 ; vaddps ymm2, ymm5, ymm2
vandps ymm7, ymm7, ymm1 ; vandps ymm5, ymm7, ymm1
vaddps ymm3, ymm7, ymm3 ; vaddps ymm3, ymm5, ymm3
vandps ymm8, ymm8, ymm1 ; vandps ymm5, ymm8, ymm1
vaddps ymm4, ymm8, ymm4 ; vaddps ymm4, ymm5, ymm4
Admittedly, writing the same code with intrinsics does not boost the performance, probably because of register renaming [4].
Why not 4x: Port 5 bottleneck
To understand the precise ceiling, let's look at what llvm-mca reports. The block reciprocal throughput is 25.0 cycles, and the resource pressure table gives the answer immediately:
SBPort0: 16.89
SBPort1: 21.08 (FP arithmetic — vaddps, vsubps)
SBPort5: 25.03 bottleneck
SBPort23: 15.00 (loads)
SBPort5 is saturated at exactly 25.03 — matching the throughput ceiling. Port 1 (FP arithmetic) and Port 23 (loads) both have remaining capacity. The bottleneck is neither compute nor memory bandwidth.
Port 5 is shared by two instruction classes that cannot be separated: the vandps instructions used for the computing abs using signmask, and all branch instructions (je, jne, jmp, etc.). In the main unrolled loop, every accumulator contributes one vandps to Port 5 — so 4 accumulators means 4x the vandps pressure on Port 5. Combined with the loop-back branch and the numerous conditionals in the tail-handling code, Port 5 becomes fully saturated. The four FP accumulators on Port 1 still have headroom; they just never get the chance to run ahead.
This is the precise reason the speedup is ~45 % rather than 4x: adding more accumulators scales Port 1 work but scales Port 5 pressure equally, and Port 5 is the ceiling.
Cosine distance: one loop vs. three
You may have a question: "Why is the SereneDB implementation of cosine distance faster — isn't it just 3 dot products?" Yes, it is. However, SereneDB computes it in one pass over the data:
Sum ll{};
Sum lr{};
Sum rr{};
for (uint16_t i = 0; i != d; ++i) {
auto li = static_cast<Sum>(reinterpret_cast<const In*>(l)[i]);
auto ri = static_cast<Sum>(reinterpret_cast<const In*>(r)[i]);
ll += li * li;
lr += li * ri;
rr += ri * ri;
}
return std::tuple{static_cast<Out>(ll), static_cast<Out>(lr),
static_cast<Out>(rr)};
In contrast, faiss computes it in three separate loops:
float norm_x = 0, norm_y = 0;
faiss::fvec_norms_L2(&norm_x, left, sz, 1);
faiss::fvec_norms_L2(&norm_y, right, sz, 1);
float product = faiss::fvec_inner_product(left, right, sz);
return static_cast<float>(product / (norm_x * norm_y));
// Actually it uses omp to compute two norms at once, but we don't use omp:
// float norms[2] = {0};
// faiss::fvec_norms_L2(norms, /*x=*/x.data(), /*d=*/d, /*nx=*/2);
// float product = faiss::fvec_inner_product(x.data(), /*y=*/x.data() + d, d);
SereneDB accumulates all three sums — ll, lr, rr — in a single pass. The vectors are loaded into cache once, and all three accumulators are updated together. Faiss reads the same data twice, paying the memory bandwidth cost repeatedly. Combined with the fastmath flags enabling multiple accumulators, this accounts for the ~13% speedup seen in the benchmark.
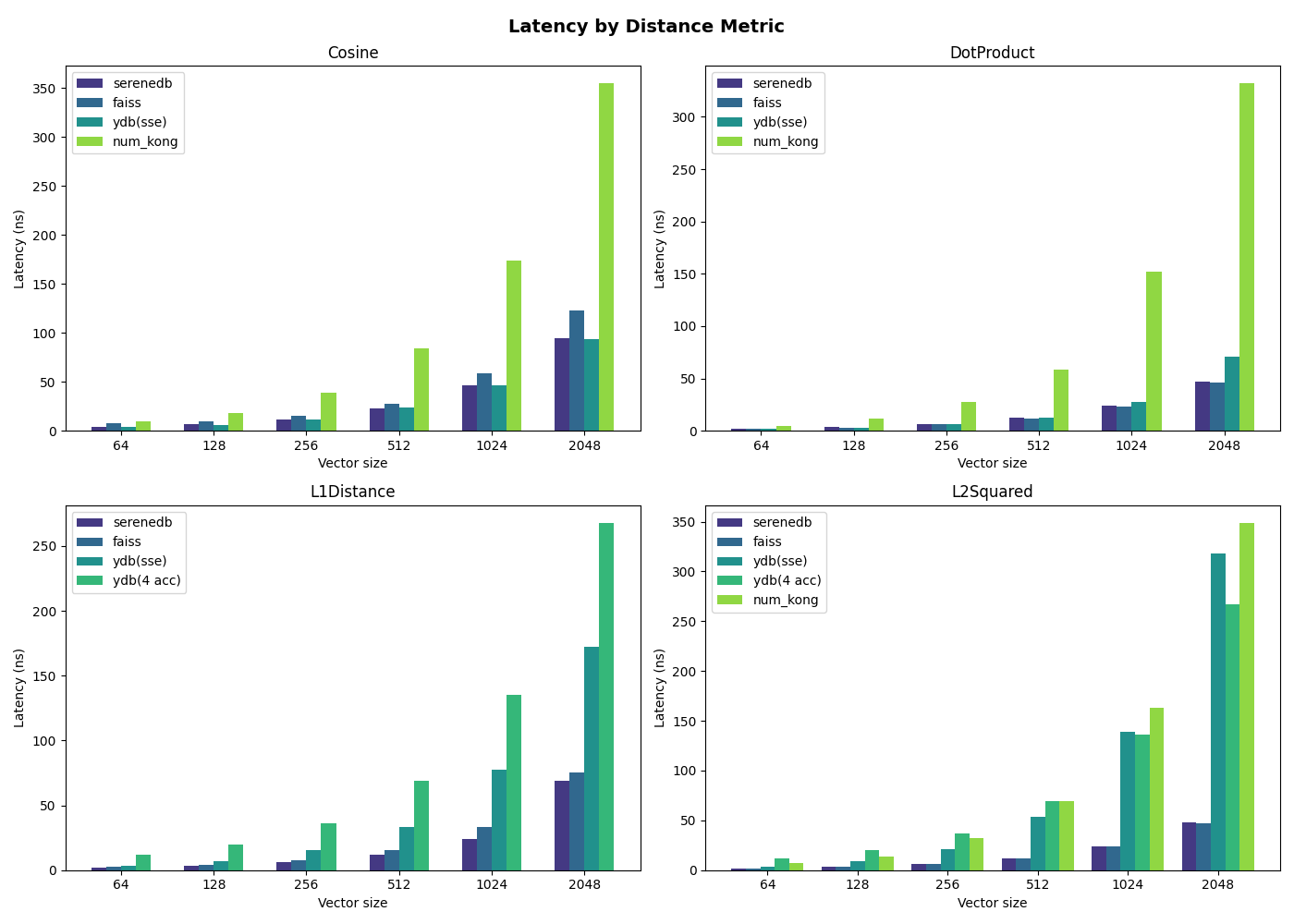
Bonus: More benchmarks!
We've also added numkong[6] and distance utils from ydb[7] (which are taken from catboost[8]) to compare with our implementation. For L1 and L2 specifically, we included two ydb implementations: one using SSE intrinsics and one using a plain loop with 4 accumulators.
numkong is significantly slower across all distances — it upcasts f32 inputs to f64 for better numerical precision, which roughly doubles the amount of data processed and prevents the compiler from fitting as many values into a single SIMD register. Therefore, it is not quite fair to compare SereneDB implementations with numkong's, since the latter has higher precision, but it is still worth mentioning.
For cosine similarity, ydb applies the same single-pass tri-way dot product trick as SereneDB, and the implementation is written using AVX2 intrinsics directly, so the cosine performance is on par with SereneDB.
For L1 and L2 we benchmarked two ydb variants. ydb (sse) is hand-written SSE implementation and is slower simply because it operates on 128-bit registers instead of 256-bit AVX2 ones, halving the effective SIMD width. ydb (4 acc) is a plain loop with 4 accumulators (the same structure as SereneDB) yet it is still noticeably slower. SereneDB computes absolute value with a single vandps against a signmask (0x7fffffff):
vsubps ymm5, ymm5, ymmword ptr [rsi + ...]
vandps ymm5, ymm5, ymm1 ; abs in 1 instruction
vaddps ymm0, ymm5, ymm0
The ydb (4 acc) source expresses absolute value as a > b ? a - b : b - a, so the compiler emits a comparison and a conditional blend instead:
vcmpltps ymm7, ymm3, ymm5 ; compare
vsubps ymm9, ymm5, ymm3 ; a - b
vsubps ymm3, ymm3, ymm5 ; b - a
vblendvps ymm3, ymm3, ymm9, ymm7 ; abs in 4 instructions
That is 4 instructions per abs versus 1, repeated across all 4 accumulators every iteration.
Replacing AbsDelta with std::abs on the subtraction result is enough to close the gap:
// before
template<typename T>
inline T AbsDelta(T a, T b) {
return a > b ? a - b : b - a;
}
s1 += AbsDelta(a[i], b[i]);
// after
auto d1 = a[i] - b[i];
s1 += std::abs(d1);
With this change the compiler recognises the pattern and emits vandps instead of the compare-and-blend sequence, bringing ydb (4 acc) to the same performance as SereneDB.
The L2 case has an even simpler explanation. Since d*d == abs(d)*abs(d), the absolute value step is entirely redundant for L2 — squaring always produces a non-negative result regardless of sign. SereneDB skips it and goes straight from subtraction to a fused multiply-add:
vsubps ymm4, ymm4, ymmword ptr [rsi + ...] ; d = a - b
vfmadd231ps ymm0, ymm4, ymm4 ; acc += d*d
Yet ydb (4 acc) still runs the full compare-and-blend sequence before squaring:
vcmpltps ymm7, ymm3, ymm5 ; \
vsubps ymm9, ymm5, ymm3 ; | unnecessary abs
vsubps ymm3, ymm3, ymm5 ; | for L2
vblendvps ymm3, ymm3, ymm9, ymm7 ; /
vfmadd231ps ymm0, ymm3, ymm3 ; acc += abs(d)*abs(d) == acc += d*d
The fix is the same — replace AbsDelta with a plain subtraction fed into vfmadd231ps.
Conclusion
Well, well, well, as a result, the simple implementation of L1 and Cosine distances is much faster (about a 45% increase in L1 distance and about 13% in Cosine distance on large vectors). Moreover, it's actually surprising how modern compilers can optimize source code. Using just a few flags, the compiler can vectorize the code and enable parallel execution with multiple accumulators.
In addition, we're planning to improve the performance by introducing a one-to-many approach like in Google's scann library. It refers to the process of taking one query vector and measuring its mathematical distance against many.
SereneDB is actively working on vector search and hybrid search — both features are coming in the next releases, so stay tuned!
If you enjoy reading about low-level optimizations, check out and star our GitHub repo: https://github.com/serenedb/serenedb.
References
[1] SereneDB vector distance implementation: https://github.com/serenedb/serenedb/blob/main/libs/iresearch/include/iresearch/utils/vector.hpp
[2] Godbolt disassembly: https://godbolt.org/z/4jse1eP7x
[3] Signed Zero: https://en.wikipedia.org/wiki/Signed_zero
[4] Register Renaming: https://en.wikipedia.org/wiki/Register_renaming
[5] Search Benchmark, the Game: https://serenedb.com/search-benchmark-game
[6] NumKong: https://github.com/ashvardanian/NumKong
[7] YDB distance utils: https://github.com/ydb-platform/ydb/tree/main/library/cpp
[8] CatBoost: https://github.com/catboost/catboost