SereneDB Team
Nov 14, 2025 · 5 minutes read
SereneDB: Real-Time Search and Analytics Database
We’re building a search database nobody thought was possible
SereneDB: Real-Time Search and Analytics Database
We’re building a search database nobody thought was possible
The Real-Time World Problem
We live in a real-time world: user activity, financial transactions, IoT sensors and application logs - all demand detection, reaction, and analysis as they happen.
Sometimes it feels like technology almost keeps up with this pace… but not quite. There’s a clear problem here - one requiring deep understanding and a clean solution. If this idea crossed your mind too at a certain point, read on! Perhaps we can build a better architecture together.
Real-time analysis isn't one simple task but a spectrum:
- Hot Data: Finding individual events - a specific user, a fraudulent transaction or a unique log entry right now. This is the 'needle in the haystack'.
- Colder Data: Moments later, this data needs aggregation - calculating 5-minute averages, p99 latencies or user cohorts. This is the 'haystack' view.
- The Update Complexity: Modern applications face constant flux. Product inventory, user statuses and order details are hit with high-volume real-time updates and deletes.

When faced with this combined challenge, developers naturally turn to search engines for how good they are at finding the ‘needle’ using complex, fuzzy or semantic queries. But it is very soon becomes clear that there’s something about the search engines that can’t be just swept under a rug:
-
They Can't Handle Real-Time Updates. Search engines were historically built for append-only workloads. Their core architecture struggles with high-volume updates and deletes. For e-commerce inventory, gaming states or threat statuses, your 'real-time' data is instantly stale.
-
They Have No Real OLAP Capabilities. You can find the needle, but you can't analyze the haystack. Search engines lack modern OLAP engines. You can't run fast aggregations, complex analytics or joins - forcing you to build a second system.
-
They Lock You Into Proprietary Ecosystems. Complex, non-standard DSLs create vendor lock-in, increase complexity and cut your team off from familiar SQL tooling.
The result: you manage multiple systems, endure data staleness and sacrifice developer productivity.
The Solution: Welcome to SereneDB
This is the challenge we're taking on with SereneDB - building a better analytics solution based on search that will back the motto: one system, one query language, one source of truth updating in real-time.
Why We Built This
For nine years, we've been building a production С++ search engine at scale. We've lived through the architectural constraints, the painful trade-offs between search and analytics, and watched teams struggle with managing multiple systems and stale data. And all these years we’ve wanted to build something that would make search a first-class citizen in the database space and wouldn’t force you to choose between finding things fast and crunching facts right.
Solving this requires rethinking a DB’s architecture from the ground up - not bolting search onto a database, but truly fusing them together.
What Makes SereneDB Different
SereneDB is built on our own Hybrid Storage Engine architecture combining:
- Advanced search indexes for fast full-text, vector and geospatial search
- A modern columnar storage for high-performance analytical queries
- A reliable row storage for true real-time updates
- The OLAP execution engine for complex aggregations and joins
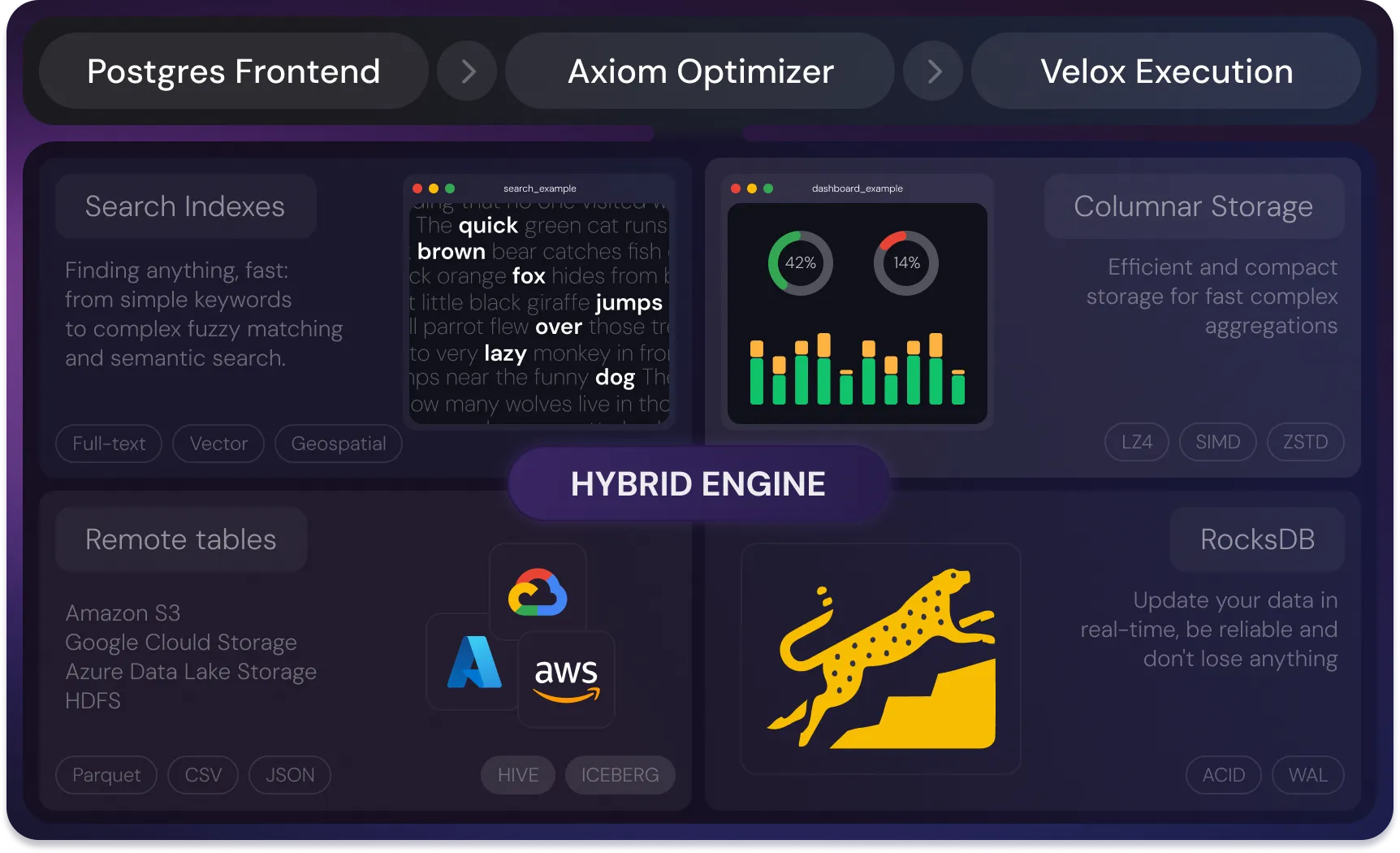
These components don't just coexist, they're architecturally fused. Search and analytics share the same data. No data movement. No synchronization lag.
Why You Should Care
Real-Time Updates
Inventory changes, status updates and modifications are reflected immediately and consistently across both search and analytical queries. No refresh delays. No staleness.
OLAP Capabilities
Run complex aggregations, joins and analytical queries on the same data you search, in the same query, using the same interface.
No Proprietary Lock-In
Write standard SQL. Connect with any PostgreSQL client. Use existing BI tools ORMs and frameworks. Set up SereneDB as a high-performance replica for your PostgreSQL database.
The SereneDB Promise
We're designing SereneDB to be powerful and convenient, and we commit to:
🕊️ Truly Open Source: The complete, single-node version will be licensed under Apache 2.0. No licensing surprises.
🔄 Efficient Real-Time Updates: Our Hybrid Storage Engine handles high-volume updates and deletes without performance anxiety. What you write is immediately available.
🚀 Superior Search Performance: Built on our next-generation search engine, designed for stress-free performance across all search techniques.
⚡️ Unified Search & Analytics: Run analytical queries that natively incorporate full-text, vector and geospatial search. One query does it all.
🐘 PostgreSQL-Compatible: Connect with any PostgreSQL client. Use existing tools and knowledge from day one.
📊 Distributed-Native: Elastic scalability and fault tolerance. Start with one node, scale to a full cluster without architectural walls.
🌐 Cloud-Native Connectivity: Query data where it lives - seamlessly access data lakes and lakehouses during execution.
😊 Intuitive UI: Manage data with a sleek interface that makes complex tasks simple.
Join the Journey
We're very early on this trail and actively building. We are working toward our open-source release early next year and will be gradually publishing code to our GitHub repository. We invite you to join us early on because we really want to hear from you and your experience, to help make SereneDB more useful for everyone.
How You Can Help:⭐ Star our repo on GitHub to spread the word
👀 Watch releases to stay updated
💬 Follow us on social channels
We're building SereneDB to revolutionize real-time analytics by making it simple, powerful and serene.
Welcome to a more serene future. Welcome to SereneDB.